Licence CC BY-NC-ND, Thierry Parmentelat
introduction¶
dans ce TP nous allons
découvrir (très superficiellement) la librairie
fletet l’utiliser pour implémenter un début de simulation de chatbot
contexte¶
on met à votre disposition deux serveurs ollama:
chacun des deux sait mettre en oeuvre plusieurs modèles d’IA (notamment
mistral, mais pas que...)l’un des deux ne possède qu’un CPU; du coup il est relativement lent mais on peut y accéder sans login/password
par contre l’autre possède un GPU, il est plus rapide pour notre application, mais le code pour s’en servir est un peu plus compliqué car il faut lui fournir un login/password
les détails de ces deux serveurs sont dans le starter code (à part les login/password qui vous seront communiqués par un autre moyen)
pour les utiliser, essentiellement on
POSTune requête http au serveur avec le chemin/api/generateen lui passant une donnée qui contientmodel: le nom du modèleprompt: la question
les détails se trouvent ici docs/api.md
objectif¶
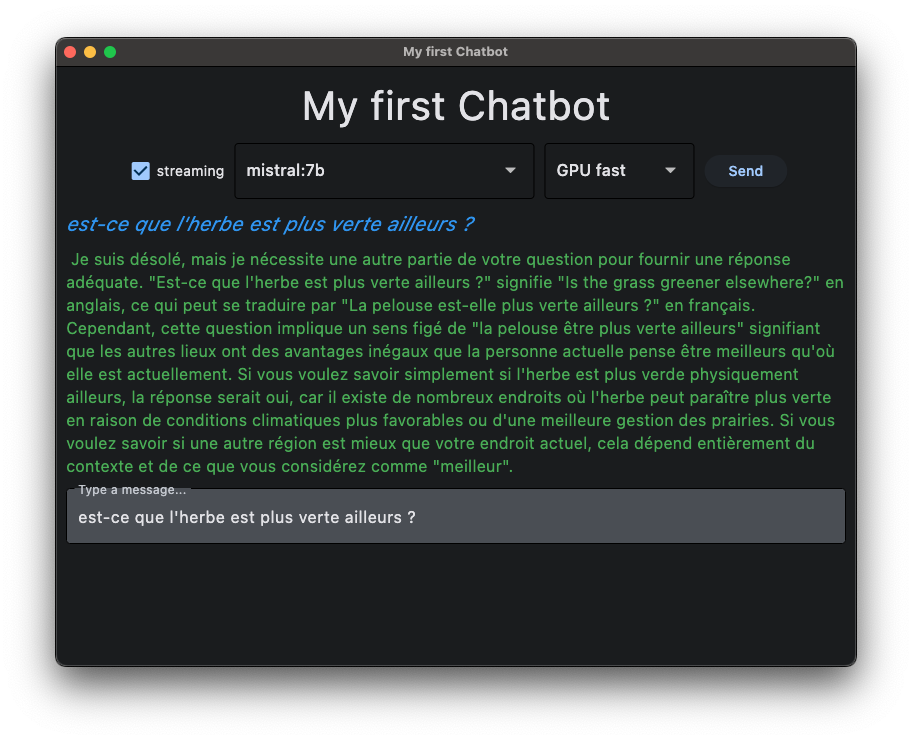
ce qu’on veut faire, c’est fabriquer une UI sommaire qui permet
de choisir le serveur,
de choisir le modèle,
et de poser ensuite des questions comme avec chatGPT
enfin sur cette implémentation on a également un bouton qui permet d’enabler le streaming
l’idée consiste à afficher les résultats “au fur et à mesure” plutôt qu’en une seule fois à la fin de l’échange avec le serveur, on en reparlera...
ça pourrait ressembler à ceci:
v01: starter code¶
"""
starter code for a chatbot - made with flet 0.25.2 (https://flet.dev)
starter code has the dialogs for choosing the model, the server, and the
streaming option, plus a button to send the request
none of this is actually connected to anything yet
"""
import os
# reads GPU_USERNAME, GPU_PASSWORD, CPU_USERNAME, CPU_PASSWORD from .env
from dotenv import load_dotenv
import flet as ft
load_dotenv()
SERVERS = {
'GPU': {
"name": "GPU fast",
"url": "https://ollama-sam.inria.fr",
"username": os.getenv("GPU_USERNAME"),
"password": os.getenv("GPU_PASSWORD"),
},
'CPU': {
"name": "CPU slow",
"url": "https://ollama.pl.sophia.inria.fr",
"username": os.getenv("CPU_USERNAME"),
"password": os.getenv("CPU_PASSWORD"),
},
}
# a hardwired list of models
MODELS = [
"gemma2:2b",
"mistral:7b",
"deepseek-r1:7b",
]
TITLE = "My first Chatbot 01"
def main(page: ft.Page):
# set the overall window title
page.title = TITLE
### the visual pieces
# a checkbox to select "streaming" mode or not - default is false
streaming = ft.Checkbox(label="streaming", value=False)
# choose the model
model = ft.Dropdown(
options=[ft.dropdown.Option(model) for model in MODELS],
value=MODELS[0],
width=300,
)
# choose the server
server = ft.Dropdown(
options=[ft.dropdown.Option(server) for server in ("CPU", "GPU")],
value="CPU",
width=100,
)
# the submit button
# what do we want to happen when we click the button ?
def send_request(_event):
"""
the callback that fires when clicking the 'submit' button
"""
# NOTE that we can use the variables that are local to 'main'
# i.e. model, server, streaming...
# for now, just show current settings
print("Your current settings :")
print(f"{streaming.value=}")
print(f"{model.value=}")
print(f"{server.value=}")
# send_request is the callback function defined above
# it MUST accept one parameter which is the event that triggered the callback
submit = ft.ElevatedButton("Send", on_click=send_request)
# arrange these pieces in a single row
page.add(
ft.Row(
[streaming, model, server, submit],
# for a row: main axis is horizontal
# and cross axis is vertical
alignment=ft.MainAxisAlignment.CENTER,
)
)
ft.app(main)
installez la librairie
copiez le code ci-dessus dans un fichier
chatbot.pyet lancez-le depuis le terminal avec
flet run chatbot.pyvous devez voir une UI un peu tristoune, avec seulement
un checkbox pour choisir le mode streaming ou pas
un dropdown pour choisir entre 3 modèles
un dropdown pour choisir entre 2 serveurs
un bouton ‘send’
à ce stade, cette UI est totalement inerte, on va la construire pas à pas
ce qu’on découvre dans la v01¶
dans ce code, on utilise le fait que
le module
fletvient avec son propre modèle de programmation; vous remarquez qu’on ne lance pas le programme comme d’habitudeen fait c’est pour offrir un mode de développement dit de hot reload, c’est-à-dire qu’il suffit de modifier un des fichiers sources, le programme s’en rend compte et recharge tout seul le nouveau code; c’est extrêmement pratique à l’usage !
et ça se concrétise aussi par le point d’entrée dans le programme, qui est
ft.app(main)
ce qu’on voit également dans ce code:
les différents morceaux de l’interface sont construits à base d’objets de la librairie; vous en voyez déjà quelques spécimens
ft.Checkbox,ft.Dropdown,ft.ElevatedButtonpour les objets visiblesft.Rowpour la logique d’assemblage
vous aurez envie de bookmark ces entrées dans la doc, pour plus d’info:
https://flet.dev le point d’entrée principal
https://
flet .dev /docs /controls pour les détails des objets disponibles
python ou flet run
on peut aussi lancer le programme de manière plus traditionnelle avec juste python chatbot.py
mais dans ce cas on n’a pas le hot reload et à l’usage, c’est une grosse différence de confort !
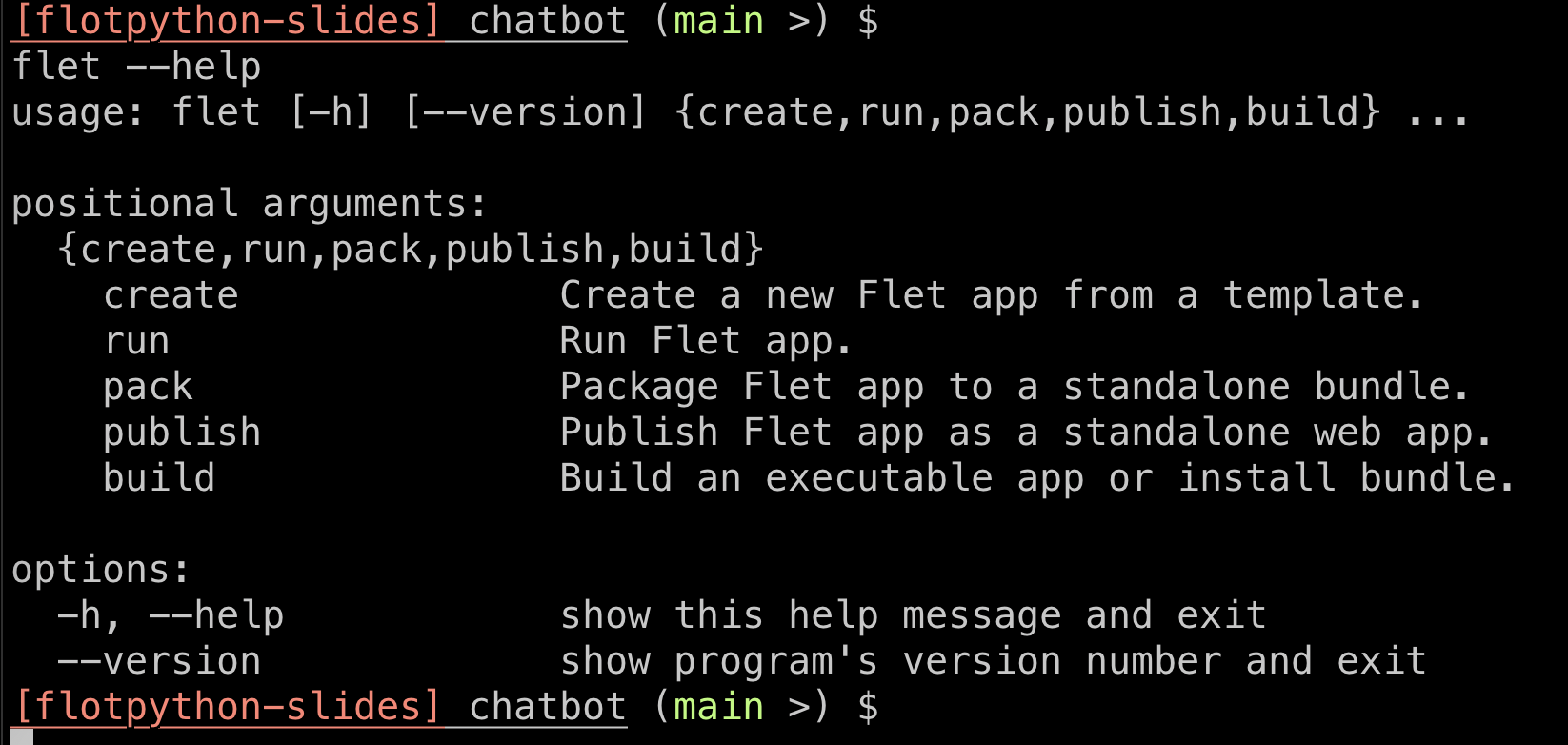
en outre il est conseillé de regarder les possibilités offertes par la CLI (i.e. le programme flet)
qui permet de faire aussi d’autres choses très utiles:
pour les forts¶
si cet énoncé vous inspire, vous pouvez simplement suivre votre voie pour développer l’application
sinon pour les autres, voici un chemin possible pour y arriver; évidemment je vous donne ces étapes entièrement à titre indicatif
bref, dans tous les cas, n’hésitez pas à faire comme vous le sentez...
v02: ajoutons un titre¶
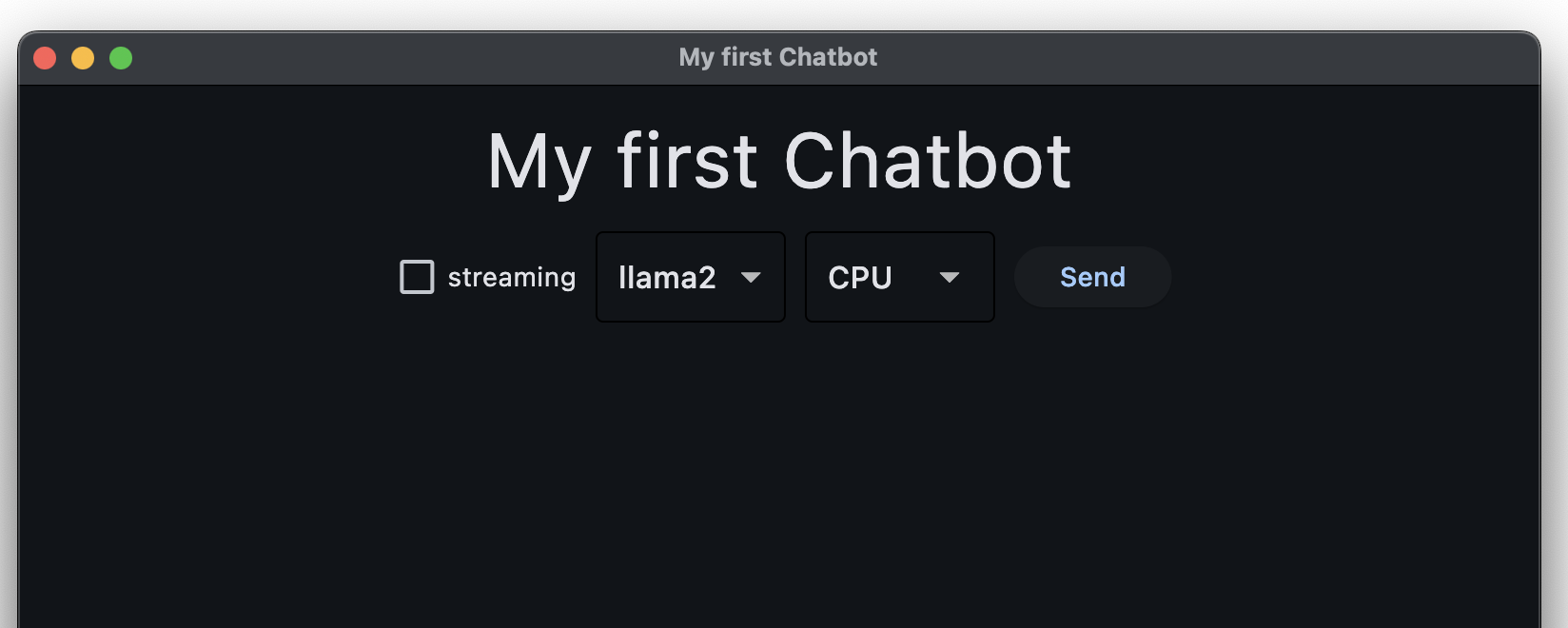
pour vous familiariser avec le modèle de lignes et colonnes de flet, ajoutez un titre principal, comme sur l’illustration
regardez
ft.Columnet
flet.Textet à chaque fois les différents attributs disponibles pour contrôler le look et le comportement de l’UI
v03: avec un peu de classe: ChatbotApp¶
ceci est une étape totalement optionnelle, mais je vous recommande de créer une classe, qui pourrait s’appeler ChatbotApp, pour regrouper la logique de notre application, et éviter de mettre tout notre code en vrac dans le main
on pourrait envisager par exemple que
ChatbotApphérite deft.Columnde cette façon on se retrouverait avec un
mainqui ne fait plus quedef main(page: ft.Page): page.title = TITLE chatbot = ChatbotApp() page.add(chatbot)
Je vous propose de procéder en deux temps
étape 3a: on crée la classe
ChatbotApp; le code demainse retrouve essentiellement dans le constructeur deChatbotApp
(et souvenez-vous comment on utilisesuper()pour initialiser la superclasse, iciColumnétape 3b: la fonction
send_requestdevient une méthode de la classe (au lieu d’être une fontion incluse dans le constructeur)
v04: une classe History¶
toujours pour éviter de finir avec un gros paquet de spaguettis, on va imaginer à ce stade d’écrire une classe History ( nouveau tout ceci est totalement indicatif...) qui:
hérite, là encore de
ft.Columnc’est elle qui est responsable de créer la zone de prompt
et d’afficher au fur et à mesure, et au bon endroit, les échanges avec le robot
de cette façon on pourra l’insérer simplement en bas dans l’objet
ChatbotAppainsi cet objet - qui rappelons-le est uneColumn- va voir maintenant 3 fils:le titre
la
Rowavec les différents réglageset une instance de
History()
pour être bien clair, à ce stade on ne fait pas encore usage du réseau pour quoi que ce soit, on veut juste mettre en place la structure de l’UI
ici encore je vous conseille de procéder par petites étapes:
4a: la trame de la classe
History4b: faites en sorte que le fait de taper “Entrée” dans la zone de prompt fasse le même effet que le bouton “Send”
v05: un peu de réseau¶
c’est seulement maintenant que l’on va effectivement interagir via le réseau avec les serveurs ollama
je vous propose pour commencer de simplement:
fabriquer la requête,
et simplement afficher la réponse dans le terminal
quelques indices:
la librairie qu’on va utiliser pour cela s’appelle
requests;vous pouvez commencer par regarder ceci pour quelques exemples https://
requests .readthedocs .io /en /latest /user /quickstart/ notre objectif ici et de bien comprendre la structure de la réponse posez-vous notamment la question de savoir quand est-ce que c’est terminé, et regardez bien la fin de la réponse
pour l’instant aussi, on ignore le flag streaming: on poste une requête et on attend le retour
à nouveau on pourra procéder par étapes:
5a: en commençant par le serveur CPU uniquement
5b: ajouter l’authentification lorsque c’est nécessaire, de façon à pouvoir utiliser indifféremment les deux serveurs
un petit exemple
voici comment on pourrait dire hey au modèle gemma2:2b
ce code peut s’exécuter par exemple directement dans ipython
import requests
import json
url = "https://ollama.pl.sophia.inria.fr/api/generate"
# c'est expliqué dans la doc ollama: l'API /api/generate
# s'attend à ce qu'on lui passe ces deux paramètres:
payload = {'model': 'gemma2:2b', 'prompt': 'hey'}
# pour envoyer une requête POST
# avec comme paramètre ce payload encodé en JSON:
# cette ligne peut prendre un moment à s'exécuter...
response = requests.post(url, json=payload)
# pour voir le status HTTP (devrait être 200)
response.status_code
# pour accéder au corps de la réponse (sans les headers HTTP)
body = response.text
# et regardez bien à quoi ça ressemble
print(body)avec authentification
dans le cas du serveur GPU qui attend une authentification:
vous pouvez simplement aménager le code ci-dessus en remplaçant cette ligne
response = requests.post(url, json=payload)par celles-ci
login_password = ('the-login', 'the-password')
response = requests.post(url, json=payload, auth=login_password)si bien que vous pouvez envisager un code un peu unifié en faisant quelque chose dans le genre de
auth_args = {}
if need_authentication:
auth_args['auth'] = ('the-login', 'the-password')
# voir le cours: on ajoute les éléments du dictionnaire
# sous la forme d'arguments nommés dans l'appel de la fonction
response = requests.post(url, json=payload, **auth_args)v06: on affiche la réponse¶
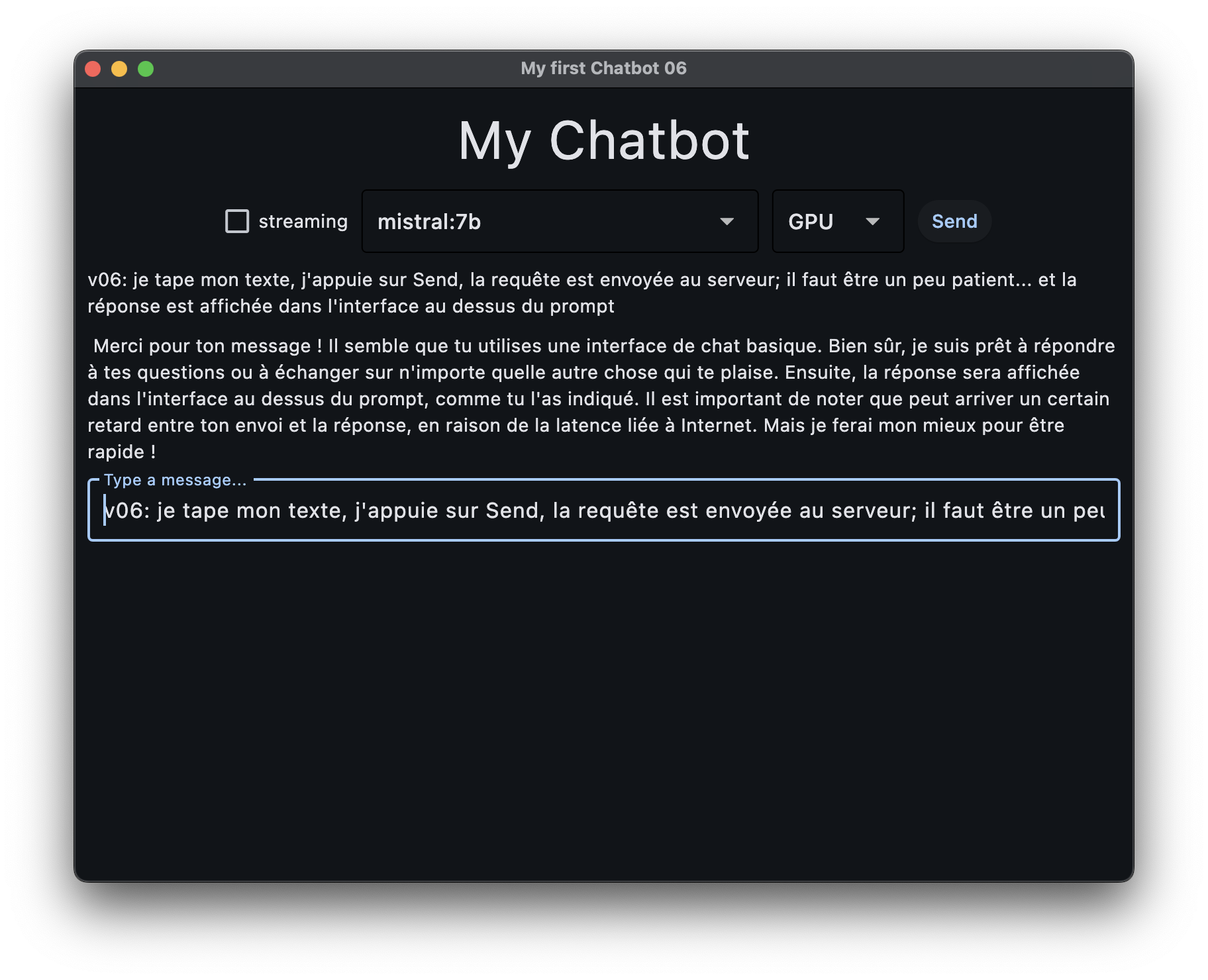
dans cette version, on utilise la réponse du serveur pour afficher le dialogue dans notre application et non plus dans le terminal
pour cela on va devoir faire quelques modifications à la classe History;
en effet vous devez avoir observé à ce stade que la réponse vient “en petits morceaux”, ce que l’on n’a pas encore prévu
du coup pour aboutir à une version à peu près fonctionnelle il devrait vous suffire de
ajouter à la classe
Historyune méthodeadd_chunk(token), qui permet d’ajouter juste un mot dans la réponse du robotet au lieu d’afficher la réponse du robot en bloc, de la traiter proprement pour en extraire les différents petits morceaux, puis les afficher dans l’interface grâce donc à
add_chunk()
v07: un peu de cosmétique¶
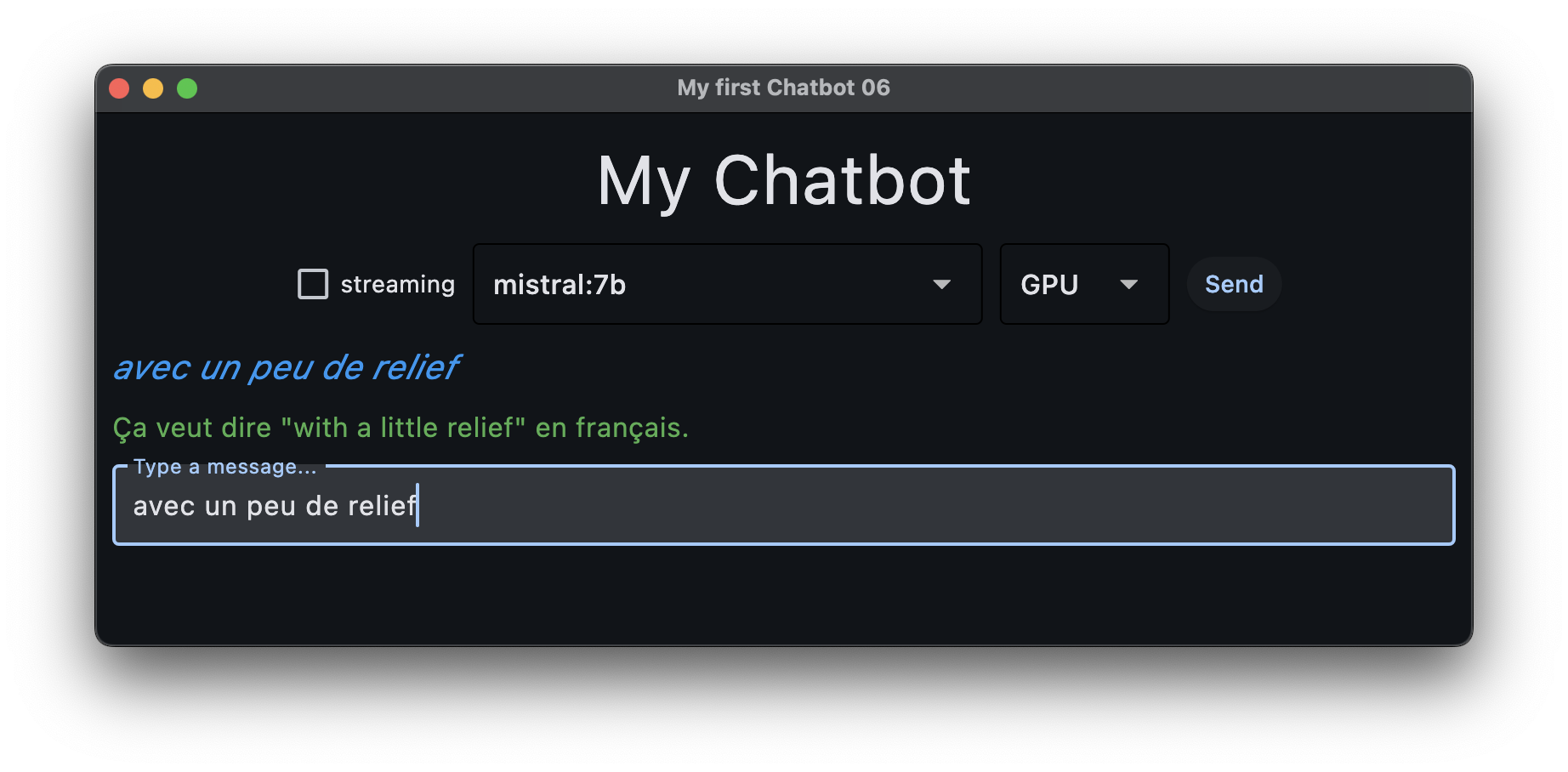
ici on va simplement ajouter un peu de relief pour qu’on s’y retrouve entre les questions et les réponses
ici aussi on peut imaginer procéder en deux étapes
7a: juste la cosmétique: montrer de manière plus distinte les 3 groupes (questions, réponses, et prompt)
7b: faire en sorte que la fenêtre scroll automatiquement vers le bas, lorsque le dialogue remplit toute la page
7c: faire en sorte qu’on ne puisse pas envoyer plusieurs requêtes en parallèle
pour 7a: de la couleur
mettre un fond de couleur à notre
TextField(le prompt)enrichir un peu l’interface de
History, et remplacer l’unique méthodeadd_message()par deux méthodes différentesadd_prompt(text)etadd_answer(text)
pour 7b: le scrolling
j’ai eu un peu du mal avec cette partie; (revenez dessus plus tard si nécessaire), mais il est important que notre chatbot scroll correctement:
c’est-à-dire qu’après plusieurs questions/réponses on voie toujours le bas du dialogue
et pour ça sachez qu’il faut procéder comme ceci
cl = ft.Column(
[....], # the children
# required so the column knows it is supposed to take all the vertical space of its father
expand=True,
# so that the widget activates scrolling when needed
scroll=ft.ScrollMode.AUTO,
# so that we're always seeing the bottom area
auto_scroll=True,
)enfin, remarquez qu’on peut avoir envie d’activer le scrolling
sur la
Columnprincipale (notreChatbotApp), mais dans ce cas les widgets de mode (streaming, server...) vont scroller aussi...
c’est mieux que pas de scroll, mais pas forcément idéal encoresur la
History, et dans ce cas les widgets de mode vont rester fixes;
dans ce cas-là toutefois, pensez à mettre tout de mêmeexpand=Truesur laChatbotApppour que les changements de la taille de l’app se propagent jusqu’à l’History
pour 7c: éviter plusieurs Send en parallèle
le sujet c’est que si le code ne fait rien de particulier, rien n’empêche l’utilisateur de cliquer 3 fois de suite sur le bouton Send, et que ça envoie 3 requêtes essentiellement en même temps
pour éviter ça, vous faites en sorte de disable les deux moyens d’envoyer la requête (le bouton Send et la touche Entrée dans le prompt)
je vous recommande du coup d’ajouter les méthodes enable_prompt() et disable_prompt() dans la classe History
et ensuite d’implémenter une logique dans la méthode send_request() pour désactiver / réactiver l’interface au bon moment; c’est peut-être d’ailleurs le moment de couper cette méthode en plus petits morceaux..
v08: supporter le mode streaming¶
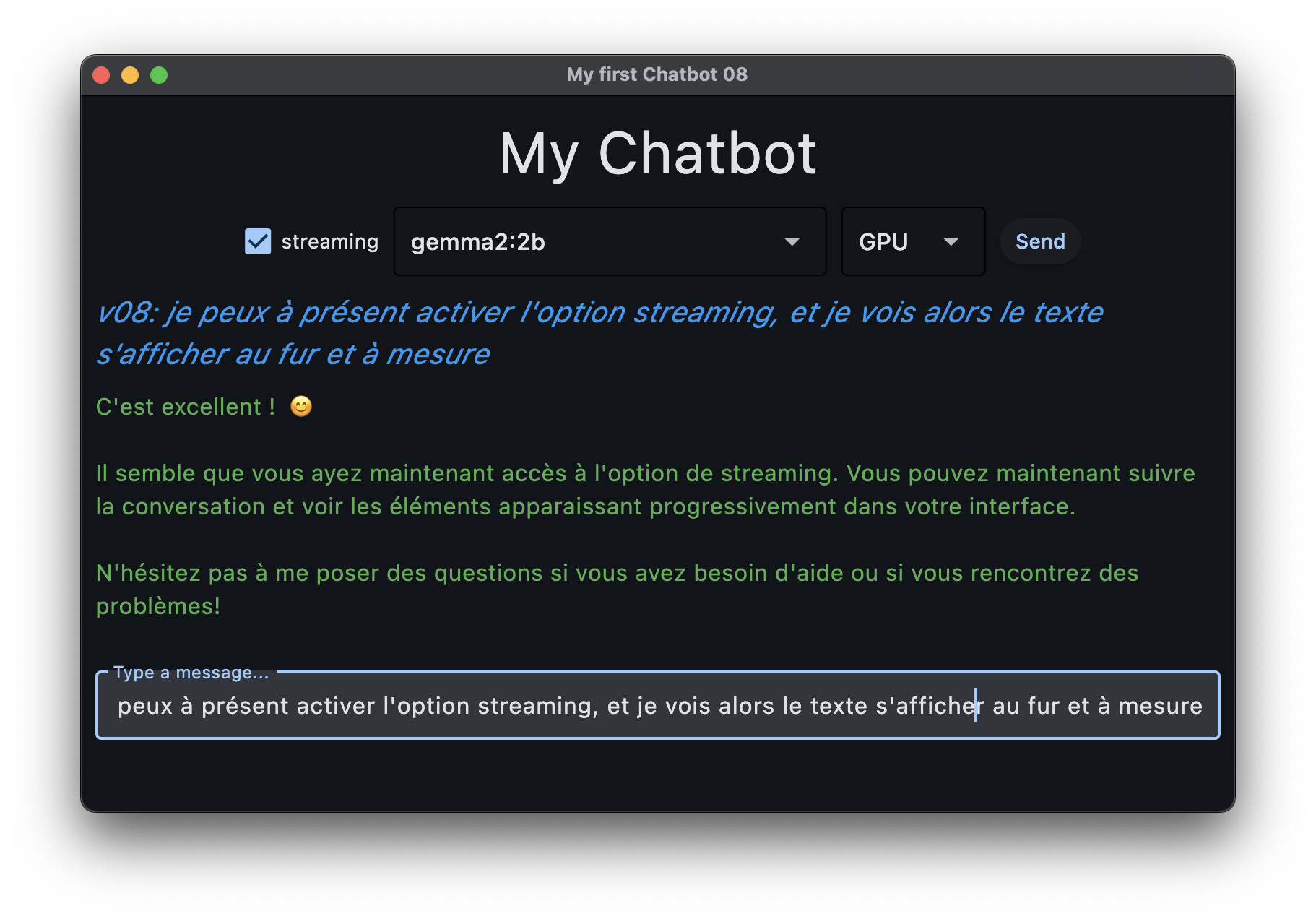
une requête HTTP “classique” est d’une grande simplicité: on envoie une requête, on reçoit une réponse
dans notre cas toutefois, ce modèle n’est pas tout à fait adapté, car l’IA met du temps à élaborer sa réponse, et on aimerait mieux voir la réponse au fur et à mesure, plutôt que de devoir attendre la fin, qui est le comportement que vous obeservez si vous avez suivi mes indications jusqu’ici
c’est ce à quoi on va s’attacher maintenant
il se trouve que le serveur ollama retourne ce qu’on appelle une réponse HTTP qui est un stream
du coup on peut facilement modifier notre code pour en tirer parti en écrivant quelque chose comme:
with requests.post(url, json=data, stream=True) as answer:
print("HTTP status code:", answer.status_code)
for line in answer.iter_lines():
# do something with the line...v09 (optionnel): acquérir la liste des modèles¶
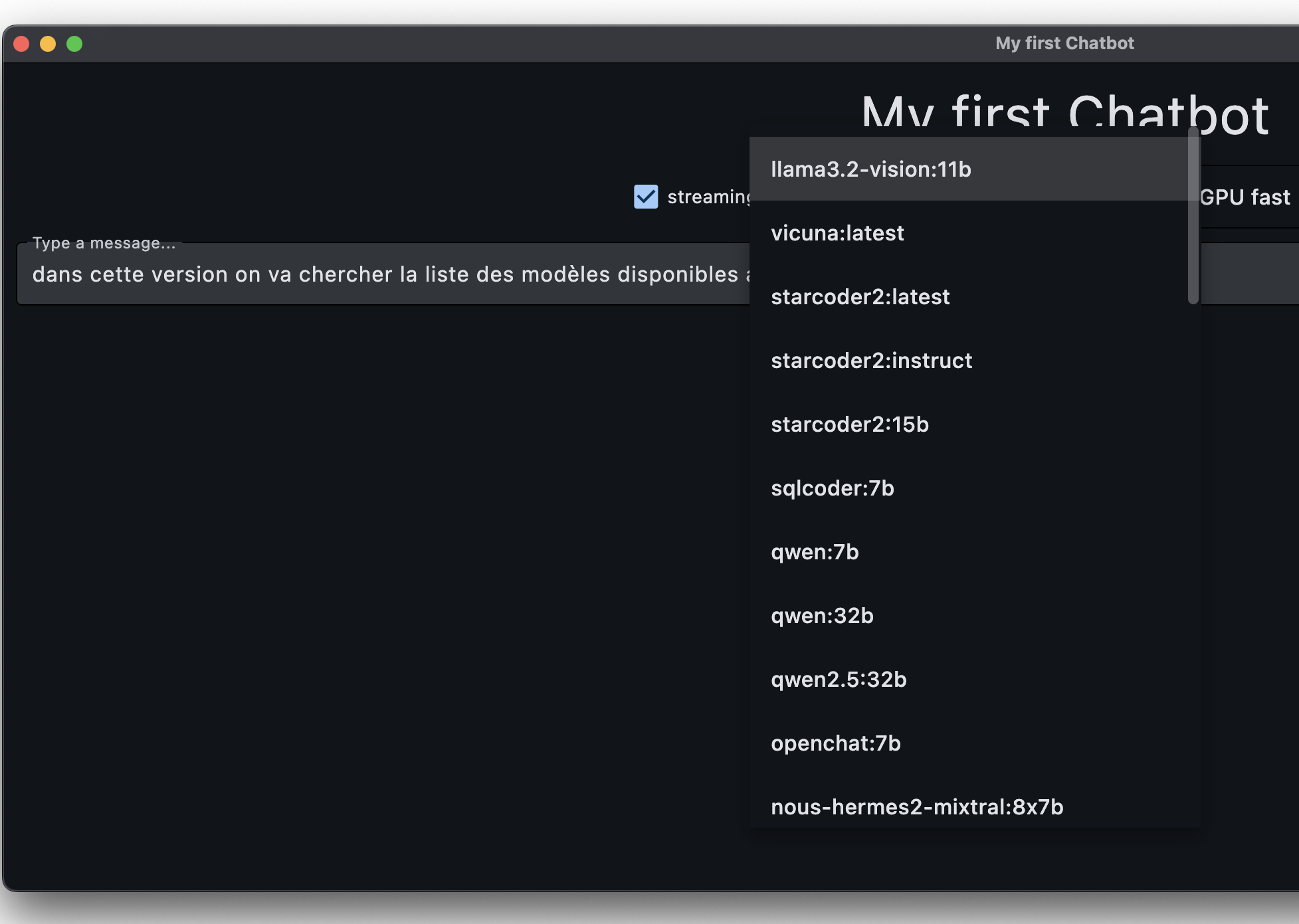
plutôt que de proposer une liste de modèles “en dur” comme dans le starter code, on pourrait à ce stade acquérir, auprès du serveur choisi, la liste des modèles connus; pour cela ollama met à notre disposition l’API /api/tags
dans mon implémentation j’ai choisi de “cacher” ce résultat, pour ne pas redemander plusieurs fois cette liste à un même serveur (cette liste bouge très très peu...); mais c’est optionnel; par contre ce serait sympa pour les utilisateurs de conserver, lorsque c’est possible, le modèle choisi lorsqu’on change de serveur...
v10 (optionnel): une classe Server¶
dans cette version, je vous propose de créer une classe Server abstraite,
qui définit une API commune pour interagir avec un serveur d’IA; puis une classe
concrète OllamaServer qui hérite de Server et qui encapsule la logique
d’interaction avec l’API ollama - puisque pour l’instant nos deux serveurs
offrent la même API
mais de cette façon dans le futur (étape suivante) on pourra plus simplement
ajouter le code pour interagir avec d’autres types de serveurs, qui implémentent
une API différente (par exemple litellm que nous avons aussi déployé à
l’Inria)
c’est pourquoi dans cette v10, je vous propose de rester à fonctionnalités
constantes, mais de créer une classe OllamaServer qui hérite de
Server et qui implémente les méthodes suivantes:
class Server:
"""
an abstract server class
"""
def list_models(self) -> list[str]:
pass
def generate_blocking(self, prompt, model, streaming ) -> list[str]:
"""
non-streaming generation - returns a list of text chunks
"""
pass
def generate_streaming(self, prompt, model, streaming) -> Iterator[str]:
"""
streaming generation - yields text chunks
"""
passv11 (optionnel): une autre API¶
à présent que nous avons une classe Server, on va pouvoir implémenter une autre classe qui hérite de Server, par exemple LitellmServer, qui implémente la même API mais en s’appuyant sur le serveur litellm-sam.inria.fr
l’API en question est documentée ici https://litellm-sam.inria.fr/#/model management/ (pour l’instant nécessite un VPN) - et sans doute à plein d’autres endroits publics
pour vous authentifier vous aurez également besoin d’une clé API - communiquée par un autre moyen
le but du jeu consiste donc ici à
implémenter une classe concrète
LitellmServerqui hérite deServeret qui implémente les mêmes méthodes queOllamaServer, mais en s’appuyant sur l’APIlitellmajouter une entrée dans le dictionnaire
SERVERSpour pouvoir choisir ce serveur dans l’interface
plein d’améliorations possibles¶
en vrac:
une fois que vous faites l’acquisition des modèles disponibles, il se peut qu’on vous retourne des valeurs de modèle qui ne fonctionnent pas;
notamment les modèlesall-minilm:22m-l6-v2-fp16' et 'all-minilm:33m-l12-v2-fp16(entre autres sans doute) ne supportent pas l’interfacegenerate
et comme - pas de bol - ils apparaissent en premier dans la liste des tags, c’est sans doute habile d’éviter de les choisir comme défaut du modèleon pourrait le savoir par programme ?sans doute; dans docs/api.md on nous montre comment obtenir des informations plus fines sur les modèles...
ajouter un bouton “Cancel” - en fait idéalement on en aurait besoin le plus tôt possible car le développement peut vite devenir fastidieux (ne pas hésiter à quitter et relancer); mais le truc c’est que c’est non trivial à faire en fait !
ou pourrait imaginer soumettre le même prompt à plusieurs modèles pour les comparer
etc...
pour aller plus loin¶
je vous signale une page pleine de tutoriels intéressants, et un peu du même genre, à propos de la librairie
flet: https://flet .dev /docs /tutorials